
Code
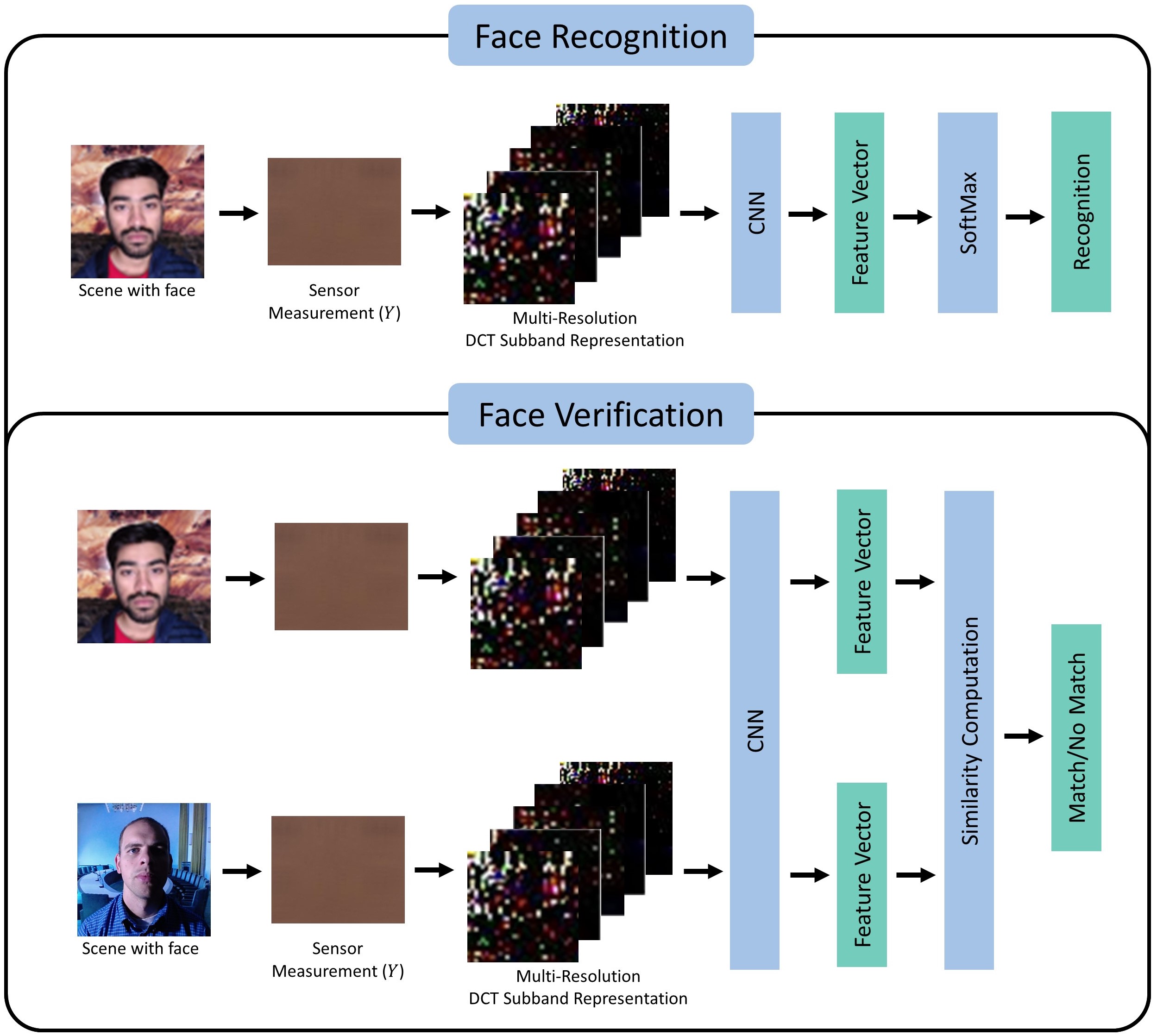
Privacy-Preserving Face Recognition and Verification using a Lensless Camera
Facial recognition technology is becoming increasingly ubiquitous nowadays. Facial recognition systems rely upon large amounts of facial image data. This raises serious privacy concerns since storing this facial data securely is challenging given the constant risk of data breaches or hacking. This paper proposes a privacy-preserving face recognition and verification system that works without compromising the user’s privacy. It utilizes sensor measurements captured by a lensless camera - FlatCam. These sensor measurements are visually unintelligible, preserving the user’s privacy. Our solution works without the knowledge of the camera sensor’s Point Spread Function and does not require image reconstruction at any stage. In order to perform face recognition without information on face images, we propose a Discrete Cosine Transform (DCT) domain sensor measurement learning scheme that can recognize faces without revealing face images. We compute a frequency domain representation by computing the DCT of the sensor measurement at multiple resolutions and then splitting the result into multiple subbands. The network trained using this DCT representation results in huge accuracy gains compared to the accuracy obtained after directly training with sensor measurement. In addition, we further enhance the security of the system by introducing pseudo-random noise at random DCT coefficient locations as a secret key in the proposed DCT representation. It is virtually impossible to recover the face images from the DCT representation without the knowledge of the camera parameters and the noise locations. We evaluated the proposed system on a real lensless camera dataset - the FlatCam Face dataset. Experimental results demonstrate the system is highly secure and can achieve a recognition accuracy of 93.97% while maintaining strong user privacy.
READ MOREView on GitHub
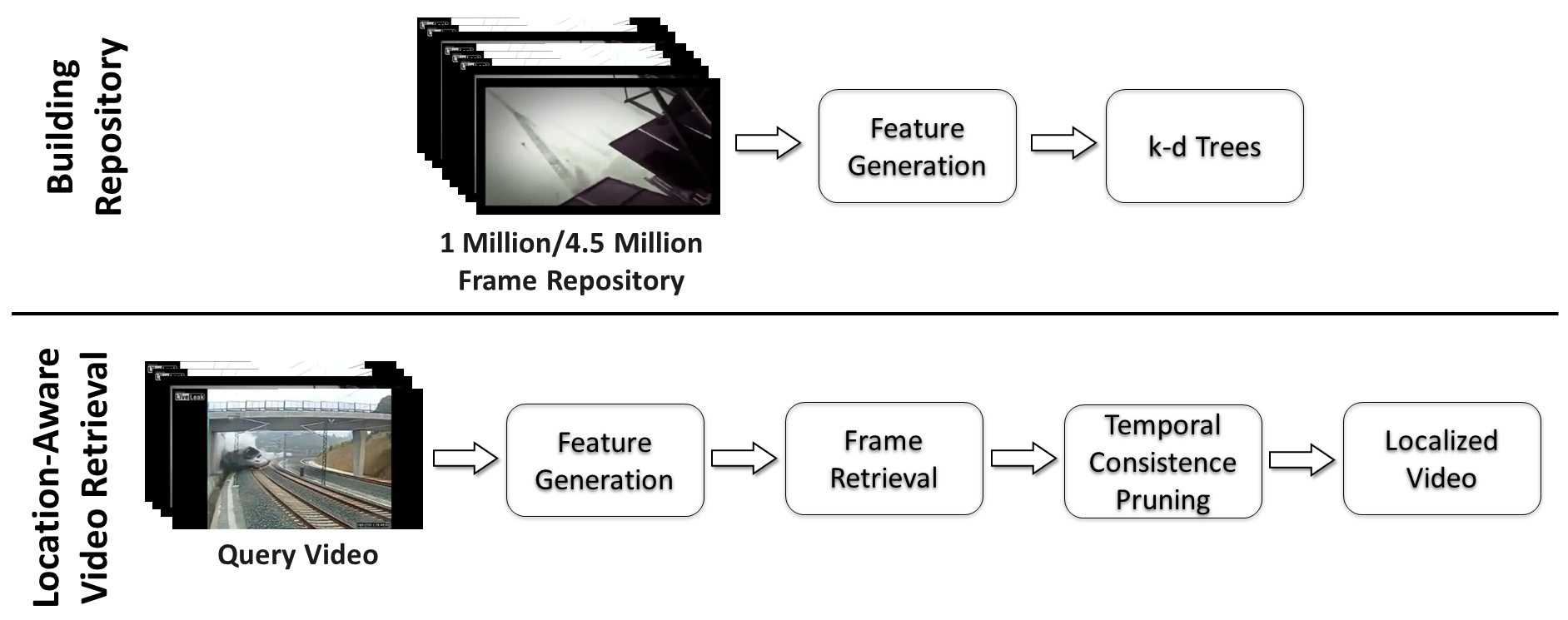
Fast Video Deduplication and Localization With Temporal Consistence Re-Ranking
The use of social media networks and mobile devices has experienced tremendous growth in recent years. This has led to a surge in the number of videos recorded and uploaded to social media platforms like TikTok and YouTube. However, this increase has also resulted in the rise of illegal duplicate videos, which are essentially the same as the original videos but with minor editing effects and variations in coding. In addition, the large number of duplicate videos is a major storage and communication efficiency issue. The task of finding duplicate videos from a large repository is referred to as video deduplication. Video deduplication is a crucial task for applications like saving storage space and detecting copyright infringement. This work proposes a fast and robust location-aware video deduplication system capable of retrieving duplicate videos from a large repository extremely quickly. In addition, the proposed system has the ability to find the precise location of the query video in the retrieved videos. To identify and localize short video clips against large video repositories, we utilize robust image-level features from keypoint aggregation and deep learning along with an efficient KNN search of query frames with a multiple k-d tree setup, giving us a set of candidate video clips. Then, a fast temporal consistence pruning algorithm re-ranks the clip-level candidates and identifies the matching clip along with its temporal location in a sequence in an efficient way. The system was tested on 1 million frame/145 hour and 4.5 million frame/636 hour repositories generated via the large-scale FIVR-200K and VCSL datasets, respectively. The proposed system achieves a recall of 98.8% and 94.1% for the FIVR-200K and VCSL datasets, respectively. A query frame is searched as fast as 83.96ms and 462.59ms from a 1 million frame/ 145 hour and a 4.5 million frame/636 hour repository, respectively. These experimental results demonstrate that our system is highly accurate and that the time consumption is extremely low for retrieving video along with its timestamp information from large-scale repositories.
READ MOREView on GitHub

E2SIFT: Neuromorphic SIFT via Direct Feature Pyramid Recovery from Events
In recent years, event cameras have achieved significant attention due to their advantages over conventional cameras. Event cameras have high dynamic range, no motion blur, and high temporal resolution. Contrary to traditional cameras which generate intensity frames, event cameras output a stream of asynchronous events based on brightness change. There is extensive ongoing research on performing computer vision tasks like object detection, classification, etc via the event camera. However, due to the unconventional output format of the event camera, it is difficult to perform computer vision tasks directly on the event stream. Mostly, works reconstruct the intensity image from the event stream and then perform such tasks. An important and crucial task is feature detection and description. Scale-invariant feature transform (SIFT) is a widely-used scale-invariant keypoint detector and descriptor that is invariant to transformations like scale, rotation, noise, and illumination. In this work, given an event voxel, we directly generate the LoG pyramid for SIFT keypoint detection. We fit a 3rd-degree polynomial and calculate the polynomial roots to compute the scale-space extrema response for SIFT keypoint detection. Since the extrema computation is performed after LoG thresholding, the solution is computationally less expensive. Experimental results validate the effectiveness of our system.
READ MOREView on GitHub